
Anmerkung der Redaktion: Dieser Text wurde ursprünglich im Entwicklungs-Blog von Slack veröffentlicht.
Wir bei Slack sind schon sehr lange konservative Technolog:innen. Anders gesagt: Wenn wir in die Nutzung einer neuen Art von Infrastruktur investieren, tun wir das mit aller Konsequenz. Das tun wir schon, seit wir 2016 die ersten ML-gestützten Funktionen herausgebracht haben, und wir haben in diesem Bereich einen stabilen Prozess und ein fähiges Team aufgebaut.
Ungeachtet dessen waren wir im letzten Jahr überwältigt davon, wie sehr sich die Funktionalität von kommerziell verfügbaren großen Sprachmodellen (Large Language Models, LLMs) verbessert hat – und noch viel mehr davon, welchen Unterschied diese Modelle für die größten Probleme unserer Benutzer:innen machen können. Zu viel zu lesen? Zu schwierig, das zu finden, was du suchst? Jetzt nicht mehr – 90 % der Benutzer:innen, die KI einsetzen, melden ein höheres Maß an Produktivität als diejenigen, die das nicht tun.
Aber wie es bei jeder neuen Technologie so ist, setzt unsere Fähigkeit zur Einführung eines Produkts mit KI voraus, dass wir eine Implementierung finden, die die strikten Standards von Slack in Bezug auf unsere Verantwortung für die Daten unserer Kund:innen erfüllt.
Die Branche für generative Modelle ist noch recht jung und setzt ihren Schwerpunkt bisher noch auf Forschung, nicht auf den Einsatz durch Unternehmenskund:innen. Es gab nur wenige Muster für Sicherheit und Datenschutz auf Enterprise-Ebene, als wir die neue Slack AI-Architektur entworfen haben.
Stattdessen sind wir von unseren Grundprinzipien ausgegangen, um die Datenbasis für Slack AI zu schaffen. Wir haben mit unseren eigenen Anforderungen begonnen – der Wahrung unserer vorhandenen Angebote für Sicherheit und Compliance und unserer Datenschutzprinzipien, wie etwa „Kundendaten sind heilig“. Dann hat unser Team mit besonderem Augenmerk auf generativer KI neue Slack AI-Prinzipien erstellt, die uns als Leitlinien dienen.
- Kundendaten verlassen Slack niemals.
- Wir trainieren keine großen Sprachmodelle (LLMs) mit Kundendaten.
- Slack AI arbeitet nur mit den Daten, die Benutzer:innen bereits einsehen können.
- Slack AI wahrt sämtliche Anforderungen von Slack an Sicherheit und Compliance auf Enterprise-Ebene.
Mit diesen Prinzipien wurde die Entwicklung unserer Architektur klarer, aber manchmal auch schwieriger. Im Folgenden möchten wir im Einzelnen erklären, wie jedes dieser Prinzipien dafür gesorgt hat, wie Slack AI heute aussieht.
Kundendaten verlassen Slack niemals.
Bei der ersten und vielleicht wichtigsten Entscheidung, die wir treffen mussten, ging es darum, wie wir sicherstellen, dass wir ein erstklassiges Basismodell verwenden können, und gleichzeitig verhindern, dass Kundendaten jemals die von Slack kontrollierten VPCs verlassen. Bei den vorhandenen generativen Modellen riefen die meisten Kund:innen von Basismodellen die gehosteten Dienste direkt auf, und es gab nur sehr wenige alternative Optionen.
Wir wussten, dass dieser Ansatz für uns nicht funktionieren würde. Sowohl wir bei Slack als auch unsere Kund:innen haben hohe Erwartungen an das Dateneigentum. Slack ist FedRAMP Moderate-autorisiert, was spezielle Anforderungen an die Compliance bedeutet – beispielsweise, dass wir keine Kundendaten an irgendeinen Ort außerhalb unserer Vertrauensgrenze senden. Wir wollten sicherstellen, dass unsere Daten unsere AWS Virtual Private Cloud (VPC) niemals verlassen, um garantieren zu können, dass niemand in der Lage sein würde, sie abzurufen oder zum Trainieren von Modellen zu verwenden.
Wir haben also angefangen, nach kreativen Lösungen zu suchen, um ein Basismodell in unserer eigenen Infrastruktur hosten zu können. Die meisten Basismodelle sind jedoch nicht quelloffen, also Betriebsgeheimnisse ihrer jeweiligen Besitzer:innen, und werden nicht einfach so an Kund:innen weitergegeben, damit diese sie auf ihrer eigenen Hardware bereitstellen.
Glücklicherweise hat AWS ein Angebot, bei dem AWS als vertrauenswürdiger Broker zwischen dem Anbieter des Basismodells und den Kund:innen fungiert: AWS SageMaker. Durch die Nutzung von SageMaker können wir nicht quelloffene, große Sprachmodelle in einer treuhänderisch geführten VPC hosten und bereitstellen. So können wir den Lebenszyklus der Daten unserer Kund:innen steuern und sicherstellen, dass der Modellanbieter keinen Zugriff auf die Daten der Slack-Kund:innen hat. Weitere Informationen dazu, wie Slack SageMaker nutzt, findest du in diesem Beitrag im AWS-Blog.
Das war die perfekte Lösung: Wir hatten Zugang zu einem erstklassigen Basismodell, das in unserer eigenen AWS-VPC gehostet wird und uns Sicherheit in Bezug auf die Sicherheit unserer Kundendaten gibt.
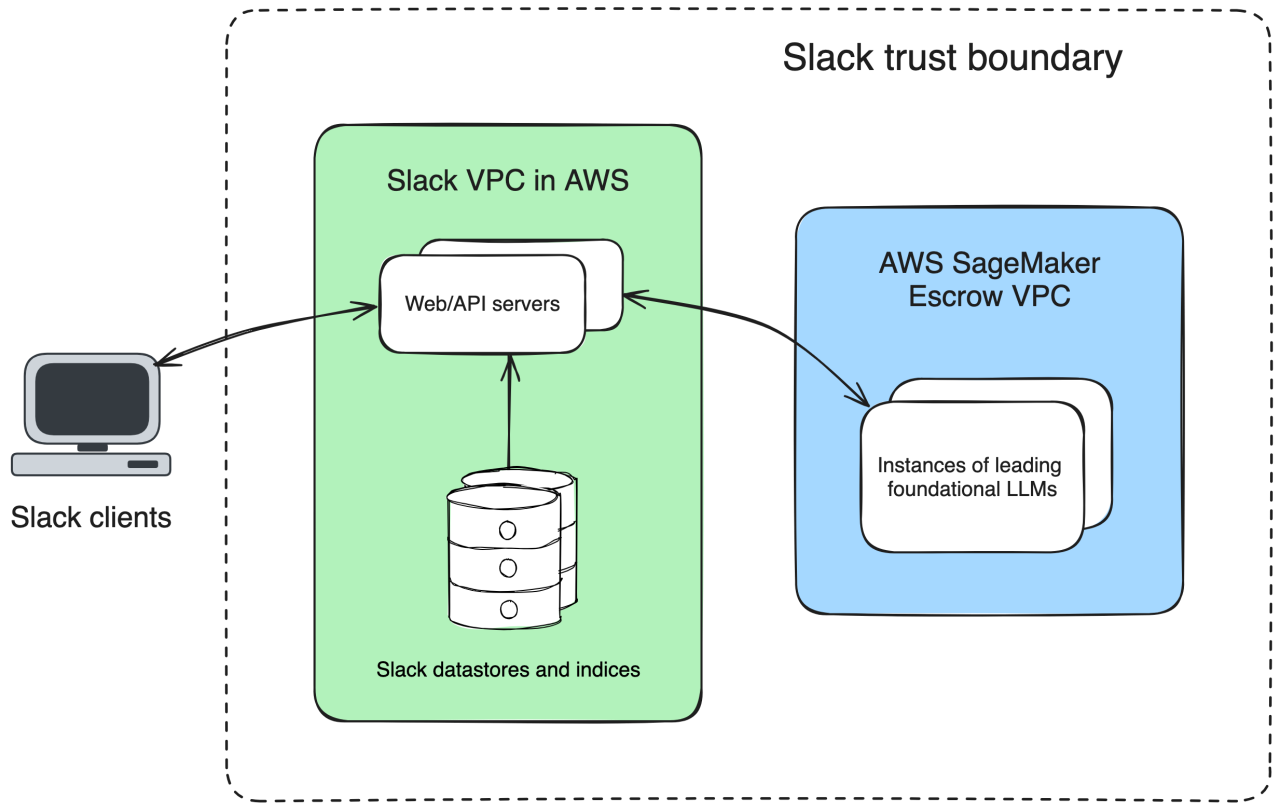
Wir trainieren keine großen Sprachmodelle (LLMs) mit Kundendaten.
Die nächste Entscheidung war ebenfalls sehr wichtig: Wir haben uns dafür entschieden, vorgefertigte Modelle zu verwenden, anstatt selbst Modelle zu trainieren oder zu optimieren. Unsere Datenschutzprinzipien gelten schon, seit wir damit begonnen haben, herkömmliche ML-Modelle in Slack zu nutzen – z. B. solche für die Ranglistenerstellung von Suchergebnissen. Zu diesen Prinzipien gehört, dass Daten niemals von einem Workspace zu anderen übertragen werden und dass wir Kund:innen Auswahlmöglichkeiten in Bezug auf diese Verfahren anbieten. Wir hatten das Gefühl, angesichts des derzeitigen noch recht frühen Entwicklungsstatus dieser Branche und Technologie keine ausreichende Garantie für diese Verfahren übernehmen zu können, wenn wir ein generatives KI-Modell mithilfe von Daten unserer Slack-Kund:innen trainieren.
Wir haben uns also dafür entschieden, vorgefertigte Modelle zustandslos zu verwenden, indem wir Retrieval Augmented Generation (RAG) einsetzen. Bei der RAG-Technik wird der gesamte Kontext, der für eine Aufgabe benötigt wird, in der jeweiligen Anforderung bereitgestellt, sodass das Modell keine dieser Daten abruft. Ein Beispiel: Zum Zusammenfassen eines Channels senden wir ein Prompt an das LLM, das die zusammenzufassenden Nachrichten sowie Anweisungen dazu enthält, wie sie zusammenzufassen sind. Die Zustandslosigkeit von RAG ist ein enormer Vorteil in Bezug auf den Datenschutz, aber auch ein Produktvorteil. Sämtliche Ergebnisse von Slack AI beruhen auf unserer eigenen Wissensbasis – nicht dem öffentlichen Internet –, was sie relevanter und präziser macht. Benutzer:innen profitieren davon, dass ihre eigenen, individuellen Datensätze verwendet werden, ohne dass die Gefahr besteht, dass ein Modell diese Daten abruft.
Bei RAG ist die Auswahl an verwendbaren Modellen möglicherweise eingeschränkt, da die Modelle über „Kontextfenster“ verfügen müssen, die groß genug sind, dass alle Daten, die in einer Aufgabe verwendet werden sollen, darin übergeben werden können. Und je mehr Kontext an ein LLM gesendet wird, desto länger dauert die Anforderung, da das Modell mehr Daten verarbeiten muss. Wie du dir vorstellen kannst, kann die Aufgabe, alle Nachrichten eines Channels zusammenzufassen, eine ganze Menge Daten umfassen.
Das war eine echte Herausforderung für uns: Wir mussten ein erstklassiges Modell finden, das ein ausreichend großes Kontextfenster und gleichzeitig eine einigermaßen niedrige Latenz bietet. Wir haben uns eine Reihe von Modellen genau angesehen und eins gefunden, das für unsere ersten Anwendungsfälle – Zusammenfassung und Suche – gut funktionierte. Es war aber bei Weitem nicht perfekt, und so haben wir uns an die Arbeit gemacht, sowohl die Prompts zu optimieren als auch weitere herkömmliche ML-Modelle mit den generativen Modellen zu verknüpfen, um die Ergebnisse zu verbessern. Das war ein langer Weg.
RAG wird mit jedem Modelldurchlauf einfacher und schneller. Die Kontextfenster werden größer, und auch die Fähigkeit der Modelle, Daten über ein großes Kontextfenster hinweg zu synthetisieren, verbessert sich. Wir sind sicher, dass wir mit diesem Ansatz sowohl die Qualität erhalten, die wir anstreben, als auch sicherstellen, dass die Daten unserer Kund:innen geschützt sind.
Slack AI arbeitet nur mit den Daten, die Benutzer:innen bereits einsehen können.
Einer unserer Grundsätze lautet, dass Slack AI nur die Daten sehen darf, die die jeweils anfordernden Benutzer:innen sehen können. Die Suchfunktion von Slack AI beispielsweise wird Benutzer:innen niemals Ergebnisse zeigen, die eine Standardsuche nicht auch finden würde. Zusammenfassungen enthalten niemals Inhalte, die die Benutzer:innen nicht auch beim Lesen der Channels sehen können.
Dies stellen wir sicher, indem wir zum Abrufen der Daten, die zusammengefasst oder gesucht werden sollen, die ACLs der anfordernden Benutzer:innen verwenden und zum Abrufen der Daten, die im Channel oder auf der Seite der Suchergebnisse angezeigt werden, unsere vorhandenen Bibliotheken nutzen.
Aus technischer Sicht war das nicht sonderlich schwierig, aber es musste eine explizite Option sein; und die beste Möglichkeit, dies zu garantieren, bestand darin, die Kernfunktionen von Slack wiederzuverwenden, darauf aufzubauen und gleichzeitig an der richtigen Stelle ein bisschen KI-Magie hinzuzufügen.
Ein Aspekt ist uns sehr wichtig: Nur die jeweiligen Benutzer:innen, die Slack AI aufrufen, können die KI-generierte Ausgabe ansehen. Damit schaffen wir die Vertrauensgrundlage, dass Slack dein zuverlässiger KI-Partner ist. Nur die Daten, die du siehst, werden eingespeist, und nur du kannst die Ausgabe sehen.
Slack AI wahrt sämtliche Anforderungen von Slack an Sicherheit und Compliance auf Enterprise-Ebene.
Es gibt kein Slack AI ohne Slack, daher haben wir sichergestellt, dass wir alle unsere Compliance- und Sicherheitsangebote auf Enterprise-Ebene integriert haben. Wir halten uns an das Prinzip „so wenig Daten wie möglich“. Wir speichern nur die Daten, die zum Ausführen einer Aufgabe erforderlich sind, und wir speichern sie nur so lange, wie sie benötigt werden.
Manchmal bedeutet „so wenig Daten wie möglich“ auch „gar keine Daten“. Wo immer möglich, sind die Ausgaben von Slack AI vorübergehend: Zusammenfassungen von Unterhaltungen und „Antworten suchen“ generieren zeitpunktbasierte Antworten, die nicht auf der Festplatte gespeichert werden.
An Stellen, an denen das nicht möglich war, haben wir möglichst viel von der vorhandenen Infrastruktur von Slack wiederverwendet und neue Unterstützungsfunktionen entwickelt, wo dies notwendig war. Viele unserer Compliance-Angebote sind in unsere vorhandene Infrastruktur integriert, wie z. B. die Verwaltung von Verschlüsselungsschlüsseln und die internationale Datenresidenz. An anderen Stellen haben wir spezielle Unterstützungsfunktionen eingebaut, um sicherzustellen, dass abgeleitete Inhalte – z. B. Zusammenfassungen – über Informationen zu den betreffenden Nachrichten verfügen. Ein Beispiel: Wenn eine Nachricht aufgrund von DLP (Data Loss Protection) zurückgestellt wurde, werden jegliche Zusammenfassungen, die aus dieser Nachricht abgeleitet werden, als ungültig markiert. Damit werden DLP und andere administrative Kontrollmechanismen zu effektiven Funktionen bei Slack AI. Dort, wo diese Mechanismen für die Nachrichteninhalte von Slack bereits aktiv waren, sind sie es auch für die Ausgaben von Slack AI.
Das waren sicher viele Informationen, und wir haben noch nicht einmal davon erzählt, wie wir Prompts erstellen, Modelle bewerten oder Anforderungsspitzen verarbeiten. Das heben wir uns für das nächste Mal auf. Es war wichtig, dass wir zuerst die Themenbereiche Sicherheit und Datenschutz behandeln, denn wir möchten, dass unsere Kund:innen wissen, wie ernst wir den Schutz ihrer Daten nehmen und wie wir diese Daten bei jedem einzelnen Schritt schützen.
 Super!
Super!
Vielen Dank für dein Feedback!
Okay!
Vielen Dank für dein Feedback.
Hoppla! Wir haben gerade Schwierigkeiten. Bitte versuche es später noch einmal!